Awk 使用教程和使用案例
本文是Awk command tutorial in linux/unix with examples and use cases的部分译文
AWK是什么?
AWK 是一个处理文本的工具。
最简单也最常用的用法的就是来获取某些文本的第N列,例如:
# file data
1 Tony 18
2 Jenny 20
$ awk '{ print $2 }' data
Tony
Jenny
AWK 的命名是取3个发明者Alfred Aho, Peter Weinberger 和Brian Kernighan名字首字母的缩写 。
AWK 内置了一种简单的脚本语言来帮助处理数据。这种语言支持变量、函数、用户自定义函数还有很多逻辑操作符。利用这个脚本语言,awk可以实现很多使用的功能
AWK使用
基础格式
awk [options] 'pattern{ commands } file'
完整格式
awk [-F|-f|-v] '
BEGIN{ commands }
pattern{ commands }
END{ commands }' file
选项
-F: 指定分隔符
-F’[:#|]’: 可以定义多种分隔符
-f: 指定脚本
-v: 定义变量 var=value
语法
pattern { action }
action类似于其他脚本语言,包含了if for while等基础的关键字
if( expression ) statement [ else statement ]
while( expression ) statement
for( expression ; expression ; expression ) statement
for( var in array ) statement
do statement while( expression )
break
continue
{ [ statement ... ] }
expression # commonly var = expression
print [ expression-list ] [ > expression ]
printf format [ , expression-list ] [ > expression ]
return [ expression ]
next # skip remaining patterns on this input line
nextfile # skip rest of this file, open next, start at top
delete array[ expression ]# delete an array element
delete array # delete all elements of array
exit [ expression ] # exit immediately; status is expression
自定义函数
awk支持用户自定义函数,一般放置在BEGIN前
function foo(a, b, c) { ...; return x }
AWK运行流程
一个awk脚本通常包含3个部分:BEGIN,BODY和END。
这3个部分都是可选的。
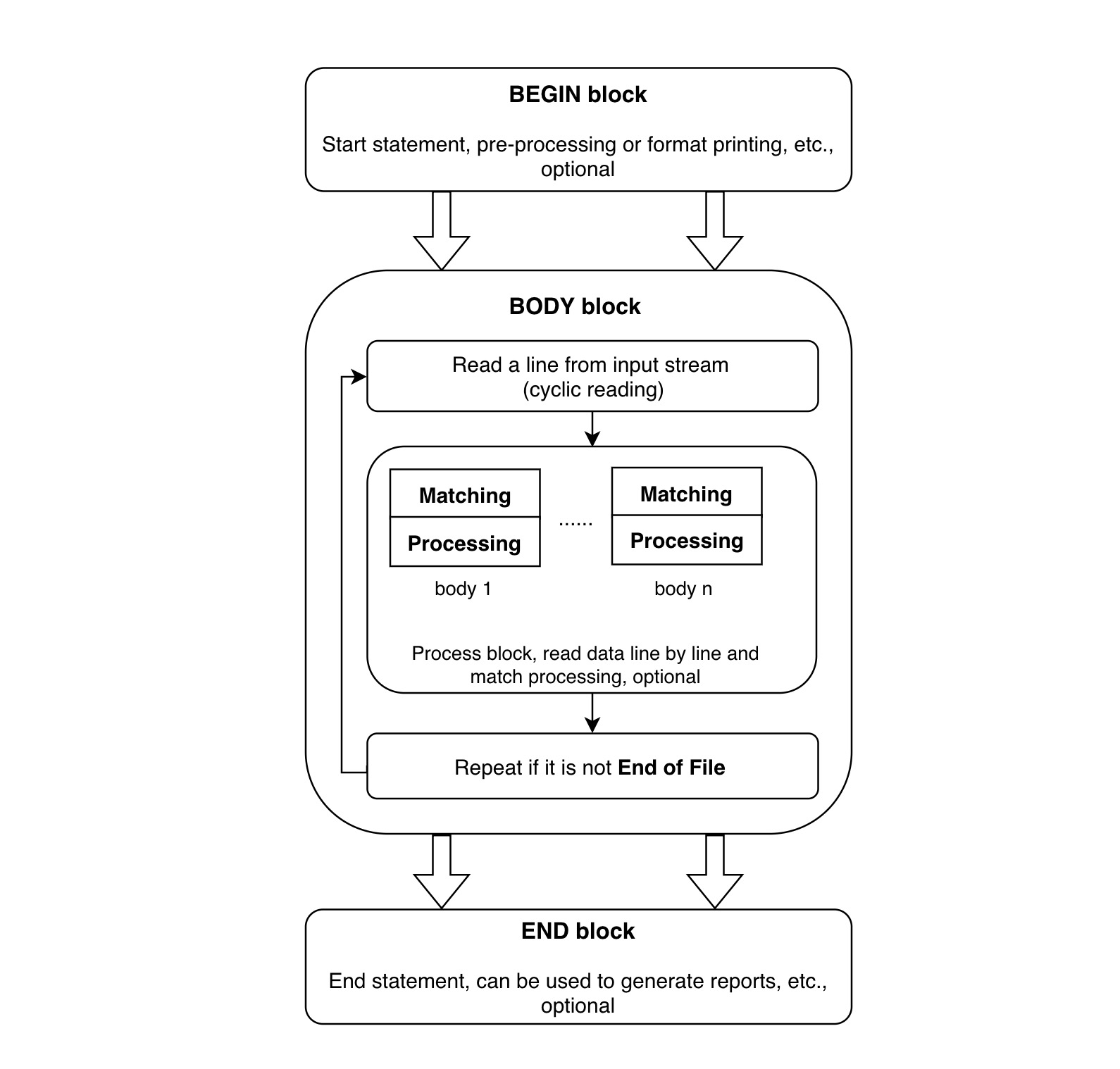
- 第1步: 执行BEGIN内的命令;
- 第2步: 从stdin或者文件逐行读取一行,然后执行匹配的命令,重复这个过程直到输入结束;
- 第3步: 读取文件结束时的时候,就会执行EN块内的命令
BEGIN 执行在读取输入之前,一般用来初始化变量和打印输出的表头或者其他辅助信息。
END 执行在读取完所有输出之后,可以用来打印一些总结统计类的信息。
BODY 包含了常用的命令,是最主要的一块。如果一个awk命令中没有BODY部分,那么BODY会默认通过{print}输出整行的记录。
变量
- $0: 代表全行
- $1: 每行的第1个字段
- NF: 字段的数量
- NR: 当前行数
- FNR: 跟NR类似,不过在处理多个文件的时候,每个文件都会重新计算行数
- FS: 定义分隔符
- RS: 定义每条记录的分割符,默认为每行一条记录
- ARGC: 参数个数
- ARGV: 参数数组
- ENVIRON: 环境变量数组
- OFS: 输出字段分隔符,默认是一个空格
- ORS: 输出记录分隔符,默认是一个换行符
操作符
+ - * / % ^ ! ++ -- += -= *= /= %= ^= > >= < <= == != ?:
- ~: 匹配(包含),模糊比较
- !~: 不匹配(不包含),模糊比较
- ==: 相等,精确比较
- !=: 不等,精确比较
这两种匹配的区别就是:
- ~ 是包含了某个字符串
- == 是两个字符串是否完全一致
数组
array[index]=value
数组不需要先声明再使用,而且index可以为任意字符,这点有点类似字典。如果index为字符,需要加上双引号。
还有awk的数组不支持多维数组,但可以利用index来模拟。留意这里也不需要加双引号。
array[1,1]=0
例子
以下的例子为显示/usr/bin目录下的应用的原始文件位置:
$ ls -l /usr/bin | awk '
BEGIN {
print "Directory Report"
print "================"
}
NF > 9 {
print $9, "is a symbolic link to", $NF
}
END {
print "============="
print "End Of Report"
}
'
其中NF > 9代表只有字段数量大于9的行才会执行BODY内的命令。
自带函数
算术函数: exp, log, sqrt, sin, cos, and atan2
其他自带函数:
- rand: 随机获取0~1之间的小数
- srand: 设置随机种子
- int: 截断数字的整数部分
- substr(string, position, length)/substr(string, position): 取子字符串
- index(s, t): 字符t出现的位置,如果没有返回0
- match(s,r): 匹配r字符串出现的位置
- split(source,des,delimiter): 通过分隔符将字符串切割,存放倒数组des
- sub(r, t, s): 按r匹配到的第一个字符串替换为t,s默认为$0
- gsub(r, t, s): 跟sub类似,替换全部匹配到的字符
- sprintf(fmt, expr, …): 格式化数据写入字符串
- system(cmd): 执行命令,并返回状态码。可以执行其他linux命令
- tolower(str): 返回全小写的字符串
- toupper(str): 返回全大写的字符串
使用案例
group by count
通常我们使用SQL来实现group by+count来归类统计某类数据,而通过awk也可以轻松实现这个功能。
示例数据:
id,name,sex
1,Tony,male
2,Jenny,female
3,Jack,male
统计男女性的人数:
awk -F, '
BEGIN {
print "---------"
print "sex total"
}
NR > 1 {
counter[$3]++
}
END {
print "male: ", counter["male"];
print "female: ", counter["female"]
}' data
匹配一定范围内的文本
以上述的数据为例,假设这段数据是包含在一个很长的文本中
...
UserData
id,name,sex
xxx
final: xxx
...
并且数据前后有明显的标识符,那么我们就可以直接使用字符匹配模式来匹配这段数据
/UserData/, /final/ { counter[$3]++ }